![[論文] SIGMOD/PODS 2024「Intelligent Scaling in Amazon Redshift」](https://devio2024-media.developers.io/image/upload/f_auto,q_auto,w_3840/v1728481803/user-gen-eyecatch/yhqgqw0rp6ecrj3rcgyg.jpg)
[論文] SIGMOD/PODS 2024「Intelligent Scaling in Amazon Redshift」
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。昨年のre:Invent2023 で発表された Amazon Redshift ServerlessでAIによるスケーリングと最適化の機能(プレビュー)が発表されました!について、データベース研究分野における最も重要な国際会議の1つである SIGMOD/PODS 2024 で、論文が発表されました。当時、「Redshift Serverlessって既に最適化機能はあるはず!」と、違いがわからなかったのですが、この論文を読むことではっきりと違いがわかりました。 まだプレビュー中の機能ですが、論文をベースに解説します。
SIGMOD’24について、Ippokratis PandisさんもXに投稿しています!
Intelligent Scaling in Amazon Redshift
ABSTRACT
クラウドベースのデータウェアハウスは使いやすさを重視して設計されていますが、ワークロードの変動に完全に自動で対応することは困難でした。この課題に対し、Amazon Redshiftは2023年に新たなAI駆動の最適化技術 RAIS(Resource Allocation and Index Selection、以降RAISと略す)をプレビューリリースしました。
RAISは垂直・水平両方のスケーリングを可能にし、大規模なクエリに対して動的にコンピューティングリソースを提供し、ワークロードの変化に応じてウェアハウスのサイズを自動最適化します。これにより、ワークロードに応じてコストや平均クエリ実行時間を最大14.2倍改善することが可能となりました。
1 INTRODUCTION
現代のクラウドデータウェアハウスは、スケーラビリティと使いやすさを重視して設計されています。これらは数回のクリックで設定でき、コンピューティングとストレージを分離して個別にスケーリングできる上、クエリが実行されていない時は自動的に課金を停止してコストを節約します。
この特性を実現するための主要なアプローチには2つあります。1つ目は、Amazon RedshiftやSnowflakeのような管理型クラスターベースのシステムで、顧客ごとに専用のコンピュートノードセットを使用します。これらのノードはアイドル時にコスト節約のためリリースされ、ワークロードが再開すると再取得されます。2つ目は、Amazon AthenaやGoogle BigQueryのような共有コンピューティングアーキテクチャで、クエリは共通のコンピューティングリソース上で実行されるように見え、個別にスケーリングできます。
クラスターベースのモデルでは、ユーザーは固定のウェアハウスサイズを選択する必要があります。サイズが小さすぎるとクエリの実行が遅くなったり、メモリ不足でディスクにスピルして性能が大幅に低下する可能性があります。逆に大きすぎると、過剰なリソースに対して支払いが発生してしまいます。また、変動するワークロードに対応することも困難です。
一方、共有コンピューティングモデルは、クエリごとに個別にリソースを割り当てる抽象化を提供することで、これらの問題の多くを解決することを約束します。しかし、このモデルにも重大な欠点があります。クラスターベースのモデルほど効率的にデータをキャッシュできず、クエリごとのオーバーヘッドも大きいため、短時間で実行されるダッシュボード型のクエリには適していません。
本論文では、AWSのre:Invent'23でプレビュー公開されたRedshiftの次世代AIスケーリング(RAIS)技術は、クラスターベースのスケーリングモデルの短所に対処し、共有コンピューティングモデルよりも優れたスケーラビリティを提供しつつ、その最大の利点である優れた価格性能比と短いクエリのパフォーマンスを維持または改善することを目指しています。
RAISの主な特長
- ワークロードに基づいて、固定のウェアハウスサイズとは異なるサイズのコンピューティングリソースを追加できる
- ワークロードを観察し、適切なベースキャパシティを自動的に決定する
- 異なるリソースサイズでのクエリ実行時間のモデルを使用して、インテリジェントにスケールアップする
- 個々のクエリのスケーリング決定を、ワークロード全体の最適化の下で統合する
- 顧客が性能向上に対してどの程度のコスト増加を許容できるかを指定できるようにする
- 顧客のワークロードプロファイルを理解し、リサイズが適切なタイミングを判断する
RAISは、クエリのクリティカルパスにある高速なオンデマンドコントローラーと、低頻度のグローバルソルバーという2つのコンポーネントを活用して、コストと性能の最適化を行います。また、メモリ消費量を推定するリソース予測モデル、未知のハードウェアサイズでのクエリパフォーマンスを推定する**「what-if」スケーリング予測モデル**、予測可能なクエリパターンを予測するワークロード予測モデルという3つの予測モデルを使用しています。
公開データセットから派生した混合ワークロードでRAISを評価し、既存の本番環境のベースラインと比較して、コストとパフォーマンスの間で有利なトレードオフを提供することを示しています。さらに、得られた教訓の要約と、研究コミュニティでまだ十分に取り組まれていない主要な研究課題についても概説しています。
2 OVERVIEW
RAISは、固定のリソースを常時提供する代わりに、ワークロードの需要に応じて自動的にリソースを拡張し、使用した分だけ課金するシステムです。各クエリに対して最適なスケーリングを行うことを目指しています。
2.1 Economics of Scaling
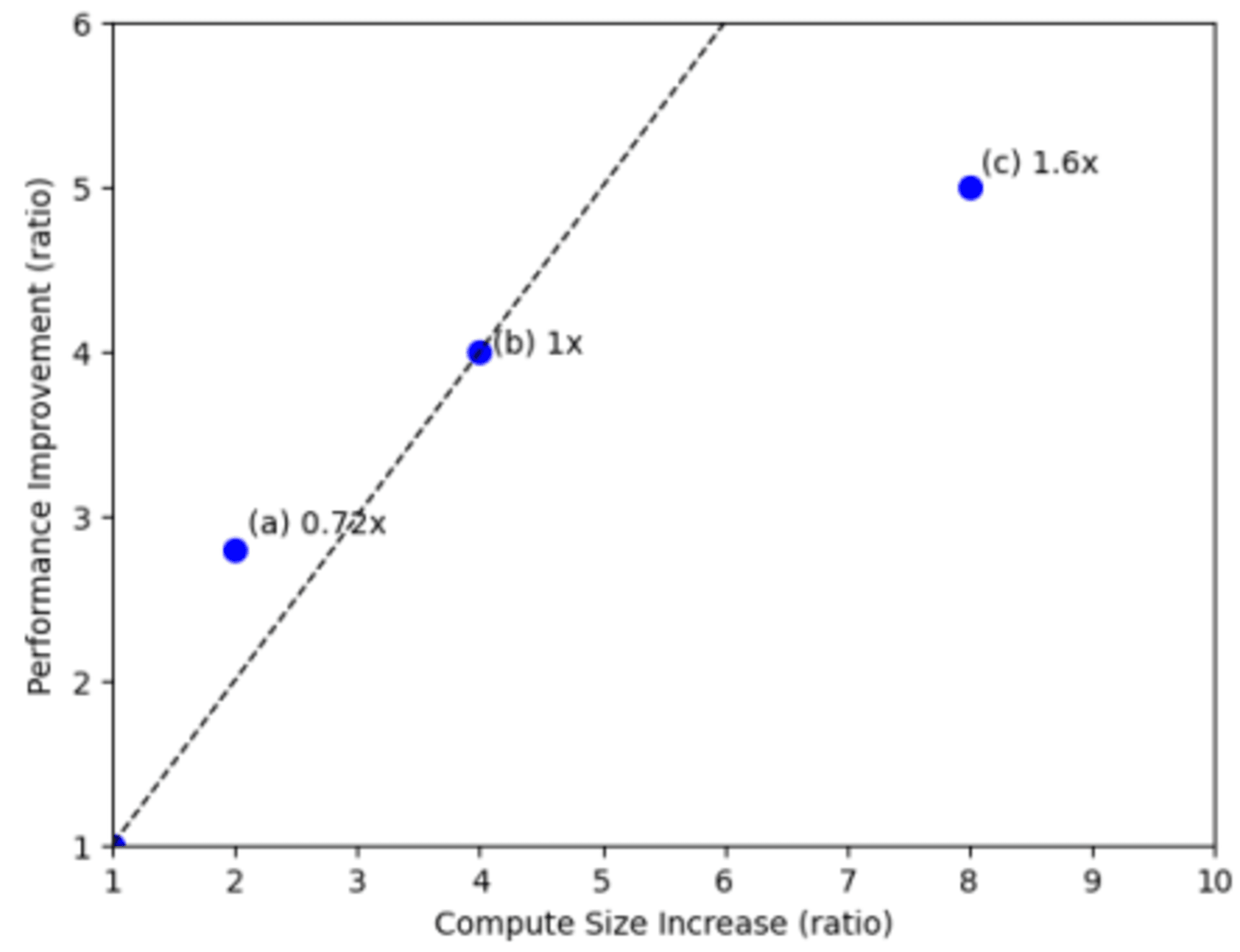
クエリのスケーリングを決定する際、計算能力がパフォーマンスに与える影響を理解することが重要です。クエリは、その特性によって3つのカテゴリーに分類されます。
- サブリニアスケーリングクエリは、リソースを倍増させても実行時間が半分以下にしか改善しません。
- スーパーリニアスケーリングクエリは、リソースを倍増させると2倍以上のパフォーマンス向上が見られます。
- 非スケーリングクエリは、リソースを増やしても実行時間が短縮されません。
しかし、実際の運用環境では、追加のコンピューティングリソースを用意することにはデメリットもあります。新しいリソースが利用可能になるまでの遅延、キャッシュ効果の減少、複数クエリの多重化による節約機会の損失などが挙げられます。
多くのワークロードでは、継続的に利用可能な「ベースキャパシティ」を持つことで、コストとパフォーマンスの両面で優れた結果が得られます。RAISシステムは、このベースキャパシティが不十分な場合にのみ、オンデマンドで追加のコンピューティングリソースをプロビジョニングします。
クエリのスケーリング決定には、顧客の価格とパフォーマンスに対する優先度も考慮する必要があります。多くのクエリはサブリニアスケーリングに分類され、より多くのリソースで実行すると高速化されますが、コストも増加します。このトレードオフが許容できるかどうかは、顧客の判断に委ねられます。
2.2 Capturing User Preferences
RAISは、顧客がコストとパフォーマンスのトレードオフを簡単に設定できるスライダーを提供しています。このスライダーは「低コスト」から「高パフォーマンス」までの5段階で設定可能で、顧客の希望に応じて右に動かすほど、パフォーマンス向上のためのコスト増加を許容することを意味します。

「1」はコストを最小化することを目指し、「100」は最高のパフォーマンスを、「50」は最も費用対効果の高い構成を表します。
RAISは顧客の過去のワークロードを使用してシミュレーションを行い、様々なパラメータに基づいてコストと平均実行時間を推定します。そして、顧客が設定したスライダーの位置に応じて、最適なパラメータを選択して実行を制御します。このアプローチにより、RAISは顧客の要求に合わせてデータウェアハウスのリソース配分とインデックス選択を最適化することができます。
2.3 Goals and Definitions
データウェアハウスは、企業が様々なソースから収集したデータを一箇所に集約し、分析・比較するためのシステムです。1980年代に概念化され、現在ではクラウド上でホストされることが多くなっています。データウェアハウスの主な目的は、ビジネスインテリジェンスを向上させ、より良い意思決定をサポートすることです。単なるデータベースとは異なり、データウェアハウスは大量の履歴データを蓄積し、高度な分析や機械学習をサポートします。その構造は通常、データの収集・変換を行うサーバー、高速クエリを実行するOLAPサーバー、ユーザーインターフェースの3層で構成されています。データウェアハウスの主なメリットには、データ品質の向上、迅速なインサイトの獲得、そして複数のデータソースの統合があります。組織のニーズに応じて、シンプルなものからステージングエリアを持つ複雑なものまで、様々なアーキテクチャが採用されています。データウェアハウスは、企業がデータドリブンな意思決定を行う上で重要な役割を果たしています。
2.4 Architecture
RAISというデータウェアハウスシステムの構成要素とその相互作用について、主要な部分はスケーリングコントローラーとポリシーオプティマイザーです。
スケーリングコントローラーは、クエリ実行のために新しいリソースを迅速に割り当てる役割を果たします。一方、ポリシーオプティマイザーは、スケーリングコントローラーの設定変更や基本コンピュートキャパシティの変更を決定します。これらのコンポーネントが協調して動作することで、効率的なリソース管理と柔軟なワークロード処理を実現しています。
3 ON-DEMAND SCALING
クエリの実行に必要なリソースを動的に割り当てる「スケーリングコントローラー」は、顧客のコストとパフォーマンスのトレードオフを考慮しながら、各クエリに対して最適なリソース割り当てを決定します。
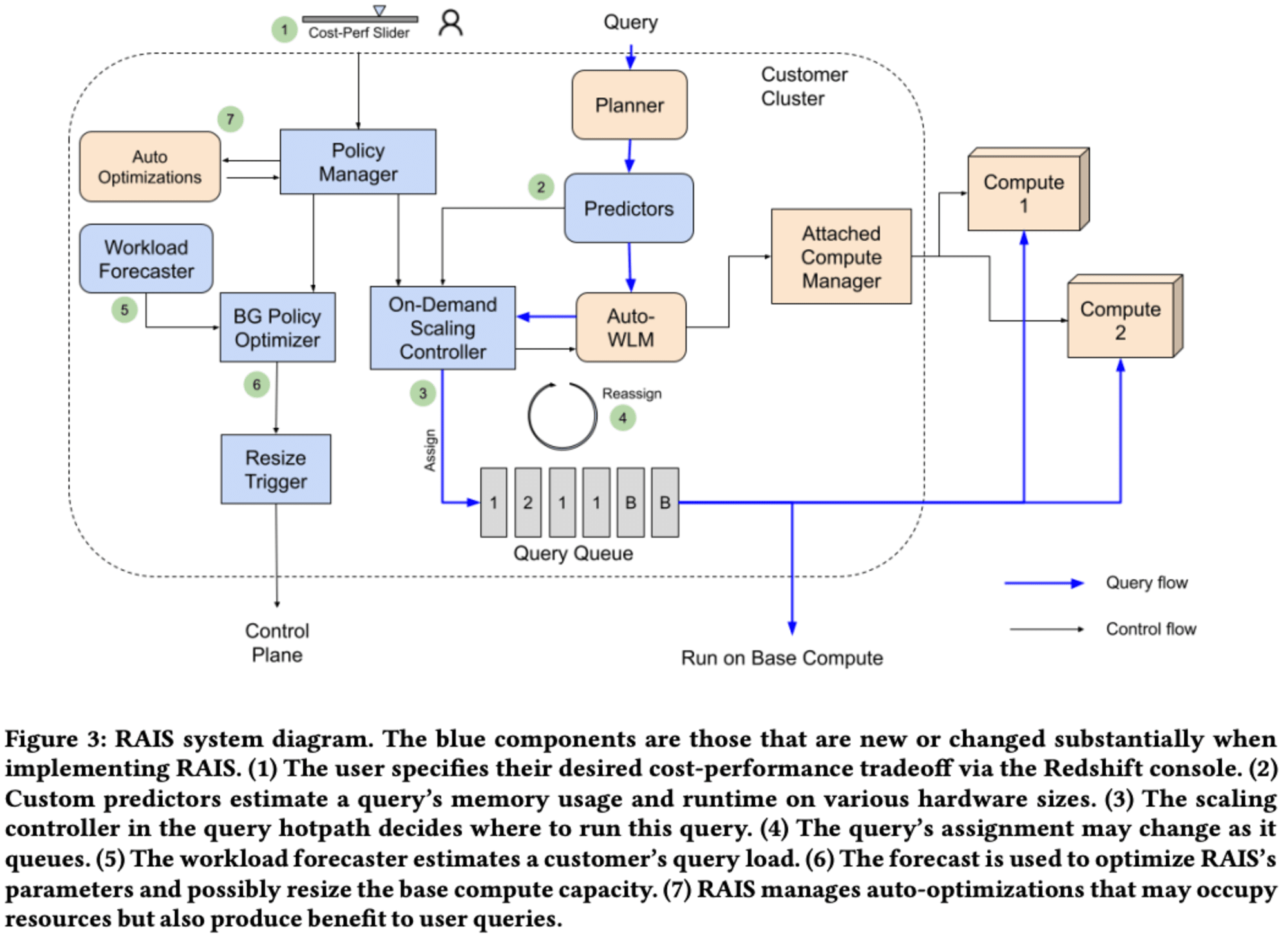
スケーリングコントローラーは、クエリの実行時間を4つの要素に分解して分析します。これらは実行時間、スピルペナルティ、キューイング遅延、準備遅延です。
- 実行時間は、クエリプランの特徴とコンピュートサイズに基づいて予測されます。
- スピルペナルティは、メモリ制約のあるクエリに対してより積極的にスケールアップするよう設計されています。
- キューイング遅延は、論理キューの待ち時間を考慮し、必要に応じて新しいリソースの追加を促します。
- 準備遅延は、新しいコンピュートリソースの準備にかかる時間を統計的に推定します。
システムは、これらの要素を組み合わせてペナルティを計算し、最適なスケーリング決定を行います。選択肢には、既存のベースコンピュートでの実行、既に取得した追加コンピュートでの実行、リクエスト済みだがまだ取得していないリソースへのキューイング、新しいリソースサイズの取得などがあります。
このアプローチの特長は、個々のクエリだけでなく、過去と将来のクエリも考慮してリソース割り当てを最適化することです。これにより、リソースの無駄を減らしつつ、効率的なクエリ処理を実現しています。また、システムは低レイテンシーを維持しながら、オンライン環境で動作するよう設計されています。
結論として、提案されているスケーリングコントローラーは、データウェアハウスのパフォーマンスとコスト効率を向上させる革新的なアプローチを示しています。動的なリソース割り当てと詳細なクエリ分析を組み合わせることで、顧客のニーズに柔軟に対応できるシステムを実現しています。
3.1 Execution Time Predictor
異なるハードウェアサイズでのクエリ実行時間を予測し、過去の誤予測から迅速に学習する手法として、Redshiftの安定した本番ワークロードでは、80%のクエリが繰り返されることにより、前回実行時の記録を使用(キャッシュ)できるため、初期のクエリ予測モデルの負担が軽減されます。
RAISシステムは、クエリの繰り返しを活用するためにキャッシュ予測エンジンを使用します。クエリはまずキャッシュで一致を確認し、一致が見つからない場合にのみクエリ予測モデルが使用されます。レイテンシに敏感なクエリのホットパスにあるため、RAISは軽量なXGBoostモデルを使用しています。
しかし、キャッシュだけでは不十分です。XGBoostモデルは「what-if」予測器であり、クエリが実際に実行されない多くの異なるコンピュートサイズでの実行時間を推定します。そのため、ほとんどのコンピュートサイズでキャッシュは効果的ではありません。ただし、1つのハードウェアサイズでの実行時間は、他のハードウェアサイズでの実行時間に関する情報を提供できます。
RAISは、多様なワークロードを持つRedshiftフリート全体で訓練されたグローバルな「ゼロショット」予測器と、クラスター自体から収集されたデータのみで訓練されたローカル予測器をアンサンブルするアーキテクチャを採用します。これにより、両者の長所を活かした予測が可能になります。
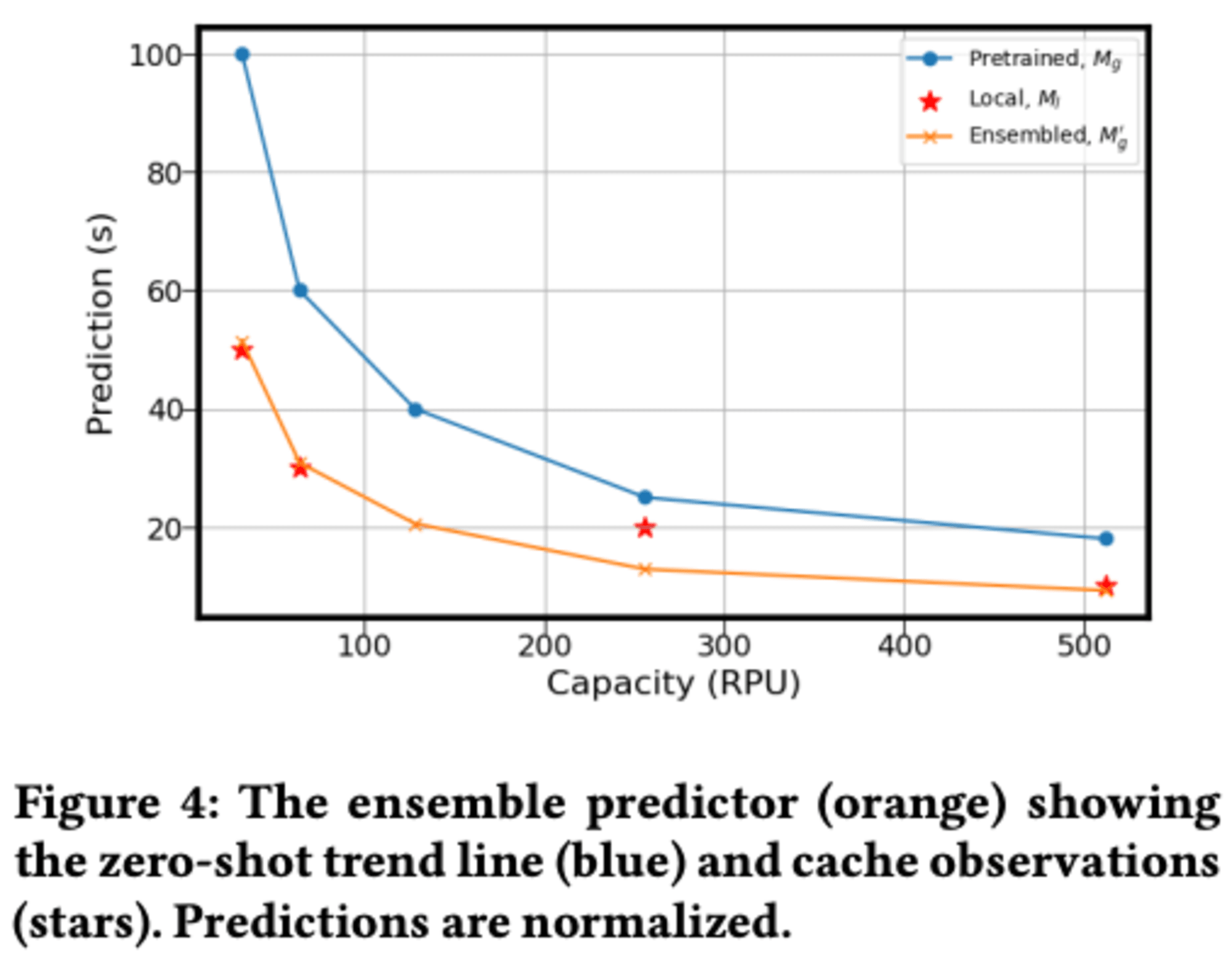
アンサンブル手法では、グローバルモデルの傾向をローカルモデルの絶対実行時間観測値に合わせてスケーリングすることで、両モデルの強みを活用します。この方法により、キャッシュされたデータポイントの数に応じて実行時間曲線の形状が調整されます。曲線の傾向は保持されたまま、キャッシュされた観測値に合わせて上下にスケーリングされます。
この手法により、異なるハードウェアサイズでのクエリ実行時間をより正確に予測し、過去の実行データを効果的に活用することが可能になります。
4 POLICY OPTIMIZER
データウェアハウスの効率的な運用を目的とした2つの重要な要素は、短期的なリソース管理を担当するスケーリングコントローラーと、長期的な最適化を行うポリシーオプティマイザーです。ポリシーオプティマイザーは、過去のワークロードを分析し、将来の需要を予測して、基本計算リソースの目標サイズとスケーリングパラメータを決定します。
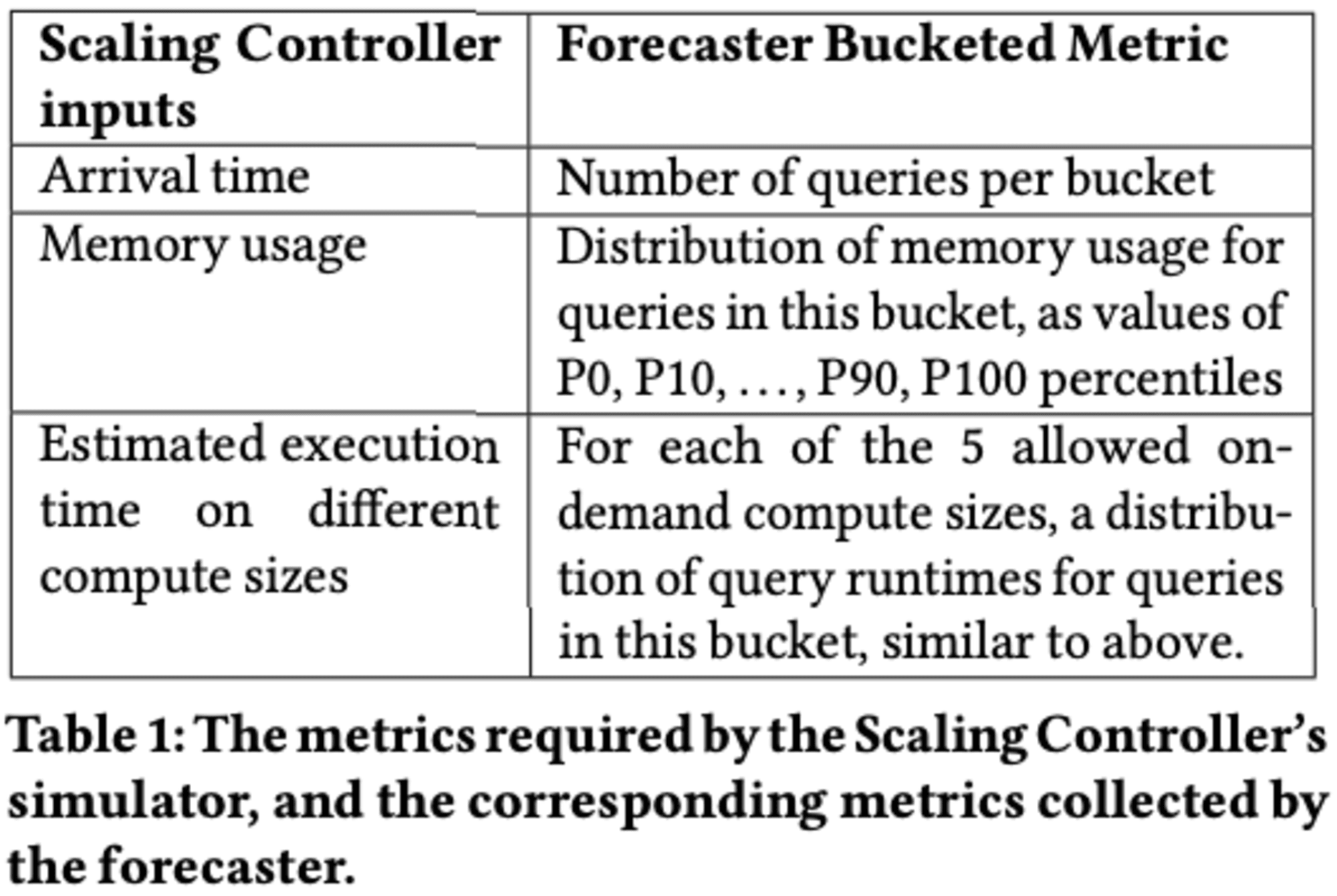
4.1 Workload Forecasting
データウェアハウスにおけるワークロード予測の目的は、日々のワークロードを予測し、基本的なコンピュートサイズを正確に見積もることです。
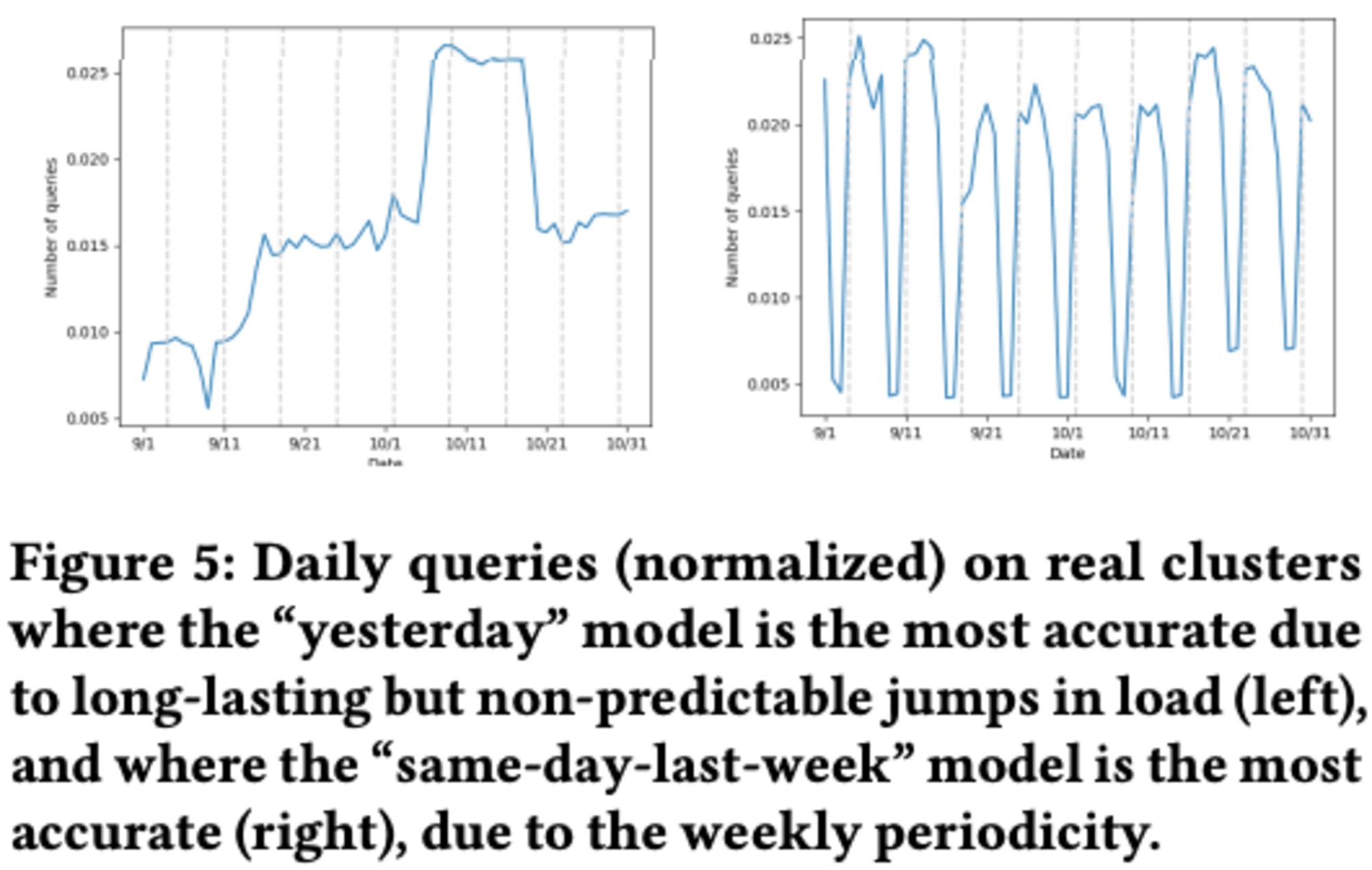
予測には、クエリごとの量が入力として必要で、5分間隔でデータを収集します。予測モデルは、過去1週間のデータから特定の日や日のサブセットを選択する方法に基づいています。具体的には、前日、前週の同じ曜日、過去1週間の平均統計の3つのモデルを使用します。これらのモデルは、多くの顧客のエンドポイントが日単位または週単位の周期性を示すことから選択されました。予測時には、過去1週間のデータに対して3つのモデルを評価し、平均二乗誤差が最も低いモデルを翌日の予測に使用します。このアプローチにより、複雑さを増すことなく、十分な精度を得ることができます。
4.2 Query Trace Generation
データウェアハウスのワークロード予測は、予測された分布からサンプリングして完全なクエリトレースを生成し、複数のトレースを作成することで、単一のパターンへの過剰適合を防ぎます。この過程で、予測の集約と再サンプリングによる精度の低下、さらに意図的なノイズの注入により、より現実的なシミュレーションを実現しています。
4.3 Simulation
データウェアハウスシステムのパラメータ調整のためのシミュレータモデルは、主に調整される2つのパラメータは、基本コンピュートサイズとスケーリングコントローラーが使用する値です。シミュレータは、各パラメータの組み合わせに対して、クエリの実行をシミュレートし、コールドスタート、スピリング、他のクエリとの同時実行による影響などを考慮に入れています。
このシミュレーションの目的は、高レベルの相互作用と競合する効果を考慮することです。例えば、クエリがより大きなリソースにスケールアップした場合、将来のクエリがそのリソースをどの程度利用するか、基本コンピュートサイズが大きい場合にオンデマンド計算の必要性が減少するか、基本コンピュートサイズが不足している場合にスピリングや過度のキューイングが発生するかなどを評価します。
RAISと呼ばれるシステムは、各パラメータ組み合わせの平均性能と総コストを基に、最適なパラメータを選択します。まず、最小コストを持つパラメータ組み合わせを特定し、その後、現在の性能レベルに応じて、コスト制約内で最小の平均応答時間を持つパラメータ組み合わせを選択します。
最後に、RAISは選択されたパラメータに基づいて、基本コンピュートキャパシティのリサイズとスケーリングコントローラーの値の更新を行います。これらの調整は、ユーザーのワークロードに適した時間、例えば基本計算がアイドル状態の時に実施されます。
この手法により、データウェアハウスシステムの性能とコストのバランスを動的に最適化し、変動するワークロードに効率的に対応することが可能となります。
5 LESSONS AND TAKEAWAYS
クラウドデータベースシステムの実運用には様々な制約があり、それらが実現可能なソリューションの種類に影響を与えます。RAISと呼ばれるシステムの導入を通じて得られた知見を共有します。
まず、システム全体のエンドツーエンドのパフォーマンスが最も重要であり、個々のコンポーネントの改善は全体的な効果が限定的であることが指摘されています。また、同じ間違いを繰り返さないことが重要で、これは熟練した人間のデータベース管理者が実現できるレベルの目標とされています。
インスタンス最適化は必要不可欠ですが、それだけでは不十分です。顧客の環境の複雑さを完全に捉えることは困難であるため、グローバルモデルとローカルな調整の組み合わせが最も効果的であることが示されています。
研究コミュニティに対して3つの重要な研究方向を提案します。
1つ目は、実行時間以外のデータベースモデルの作成です。メモリ消費量やCPU要件の予測など、より信頼性の高い性能指標の開発が求められています。
2つ目は、21世紀版のアムダールの法則の必要性です。クラウド環境では、クエリの並列化がより複雑になっており、従来の単純な直列部分と並列部分の分割では不十分です。クラウドでのクエリのスケーリング挙動の理解が、より堅牢な最適化アルゴリズムの開発につながると指摘されています。
3つ目は、グローバルとローカルのアプローチを組み合わせたインスタンス最適化の妥当性についてです。データベースシステムのどの部分がローカルなインスタンス最適化に適しており、どの部分がグローバルな分析に適しているかを明らかにすることが重要です。
これらの研究方向は、Redshiftのようなクラウドデータベースに直接的かつ実用的な影響を与える可能性があり、データウェアハウス技術の将来を形作る上で重要な役割を果たすと考えられています。
6 EVALUATION
Redshift ServerlessにおけるRAISの実装は、オンデマンドおよびバックグラウンドスケーリングコンポーネントを通じて、パフォーマンスとコストの最適化を図ります。評価では、平均レイテンシーと95パーセンタイルレイテンシー、そしてRPU秒単位で測定されるコストが考慮されています。
RAISの主な特長として、クエリの複雑さに応じたスケーリング能力があります。これにより、既存の本番環境のベースラインと比較して、データベース展開の価格または性能を最大8倍から10.72倍改善することが可能です。また、**RAISはデータサイズに応じてベースコンピュートサイズを調整し、過剰プロビジョニングの場合はスケールダウン、不足の場合はスケールアップを行います。**この継続的なリサイジングにより、価格性能を最大2倍向上させることができます。
さらに、RAISはスライダー位置に基づいてコストとパフォーマンスのトレードオフを行うため、顧客は必要に応じてより高速なパフォーマンスを得るために追加コストを支払うことができます。これらの特長により、RAISは柔軟で効率的なデータウェアハウス管理を可能にし、ユーザーのニーズに応じた最適化を実現します。
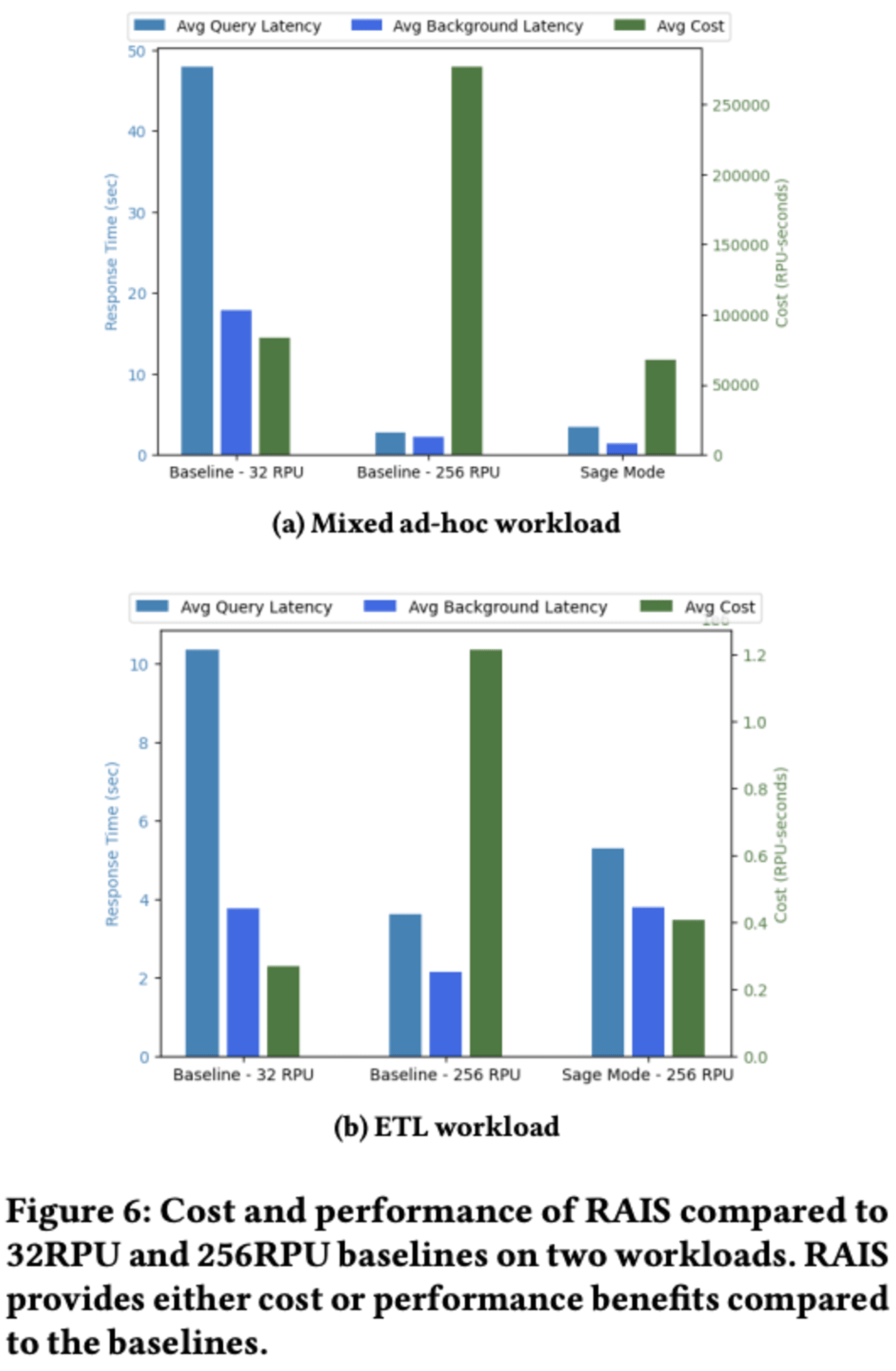
6.1 On-Demand Scaling
データウェアハウスにおける混合ワークロードとETLワークロードに関する研究について解説します。
研究者たちは、TPC-DS 3Tベンチマークを用いた混合ワークロードを使用し、RAISという新しいシステムと現行Redshift Serverlessを比較しました。混合ワークロードでは、RAISがコストを2.94倍削減するか、平均実行時間を14.2倍改善することが示されました。
特に、アドホッククエリの処理において、RAISは静的な計算能力を持つシステムよりも優れた性能を発揮しました。例えば、大規模なクエリの待ち時間を928秒から25秒に短縮し、37倍以上の改善を達成しました。
ETLワークロードに関しては、RAISはショートクエリと大規模なコピークエリが混在する環境で、コストまたは性能を2〜3倍改善しました。
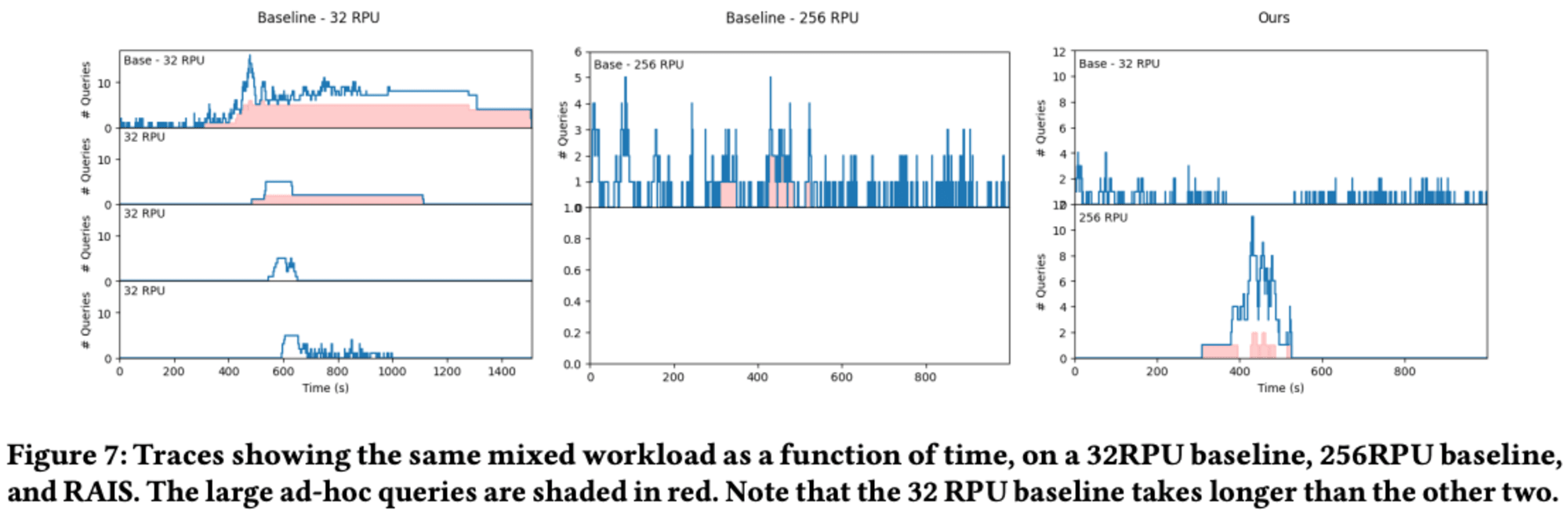
重要な点として、ワークロードの長さがコストと性能の改善に大きく影響することが示されました。例えば、12時間の短いクエリの後に目標のウィンドウが続く場合、32 RPUベースラインに対する性能改善は小さくなりますが、256 RPUベースラインに対するコスト改善は大きくなります。
総じて、RAISは予測不可能な混合ワークロードや日次ETLジョブに対して、顧客の監視を必要とせず、コストと性能のバランスを自動的に最適化できる有望なソリューションであることが示唆されています。
6.2 Resizing Base Compute
RAISと呼ばれるシステムの能力評価について述べています。RAISは、ワークロードに応じてベースとなる計算リソースを適切にスケーリングする機能を持っています。このスケーリングの決定は、ポリシーオプティマイザーによって制御されます。
評価は主に2つの方向性で行われました。1つ目は、ワークロードが軽すぎる場合にRAISがベース計算リソースを縮小できるかどうか。2つ目は、テーブルサイズが増加してクエリが遅くなった場合に、RAISがベース計算リソースを拡大できるかどうかです。
スケールダウンの評価
128 RPU(Redshift Serverlessのデフォルト)のエンドポイントサイズから始め、パフォーマンスレベルを1(最もコスト重視)に設定しました。TPC-DS 100Gワークロードを10分ごとに12時間実行し、その後RAISがベースコンピュートキャパシティを評価してリサイズを決定しました。
結果は、スライダーレベルが下がるにつれてベースコンピュートサイズが減少し、スライダーレベルが上がるにつれてパフォーマンスが向上することを示しました。ただし、スライダーレベル100(112 RPUに相当)では、クラスターがワークロードに対して大きすぎるため、パフォーマンスが低下し始めました。RAISは、このワークロードに対してはより小さなクラスターサイズの方がパフォーマンスが良いことを認識し、それ以上大きなサイズを選択しませんでした。
スケールアップの評価
32 RPUの小さなベース計算から始めました。TPC-DS 3Tをベースにした15分の軽いワークロードを実行し、各クエリは単独で2秒未満で実行されるものを使用しました。毎日、TPC-DS 1Tのファクトテーブル("-sales"または"-returns"で終わるもの)のコピーを挿入し、ワークロードを再実行しました。
パフォーマンススライダーを1に設定し、コスト重視の顧客を想定しました。結果は、テーブルサイズが毎日増加するにつれてクエリ実行時間が増加することを示しました。これは、各クエリがより多くのデータをスキャンする必要があるためです。RAISは毎日最小コストの構成を探しましたが、最初の2日間は変更を行いませんでした。
**3日目に、RAISは元のサイズ32 RPUが小さすぎると判断し、エンドポイントを動的に64 RPUにサイズアップしました。**その結果、実行時間が2倍以上短縮されました。
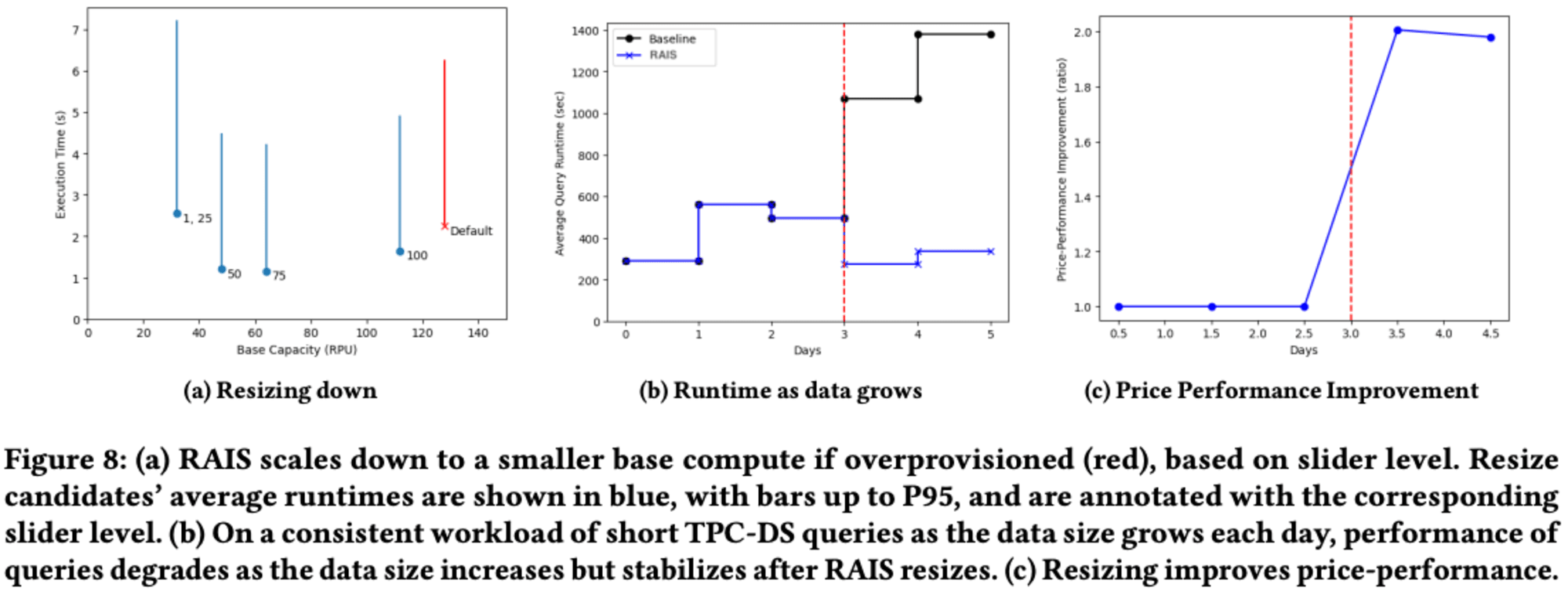
しかし、パフォーマンスの向上だけでは、RAISが正しくリサイズしていることを示すには不十分です。例えば、RAISが256 RPUのような大きなコンピュートキャパシティを選択すれば、クエリは高速化されるかもしれませんが、このコスト重視の顧客にとっては高すぎる料金になってしまいます。
RAISは適切な場合にのみリサイズを選択し、コストを不必要に上昇させないサイズを選ぶ必要があります。論文の結果は、RAISがリサイズした後、ワークロードの価格パフォーマンスが2倍向上したことを示しています。これは、リサイズの決定がベースラインよりも好ましかったことを示唆しています。
この研究は、RAISシステムがワークロードの変化に応じて適切にリソースをスケーリングし、コストとパフォーマンスのバランスを取る能力を持っていることを示しています。これは、データウェアハウスの運用において、効率的なリソース管理と費用対効果の高いパフォーマンス最適化が可能であることを示唆しています。
6.3 Changing Performance Level
データウェアハウスの性能とコストのトレードオフに関する研究の結果、ユーザーが設定したスライダーの値に基づいて、計算リソースの割り当てを動的に調整します。スライダーの値が高いほど、システムはより積極的にリソースを追加し、性能が向上しますが、コストも増加します。
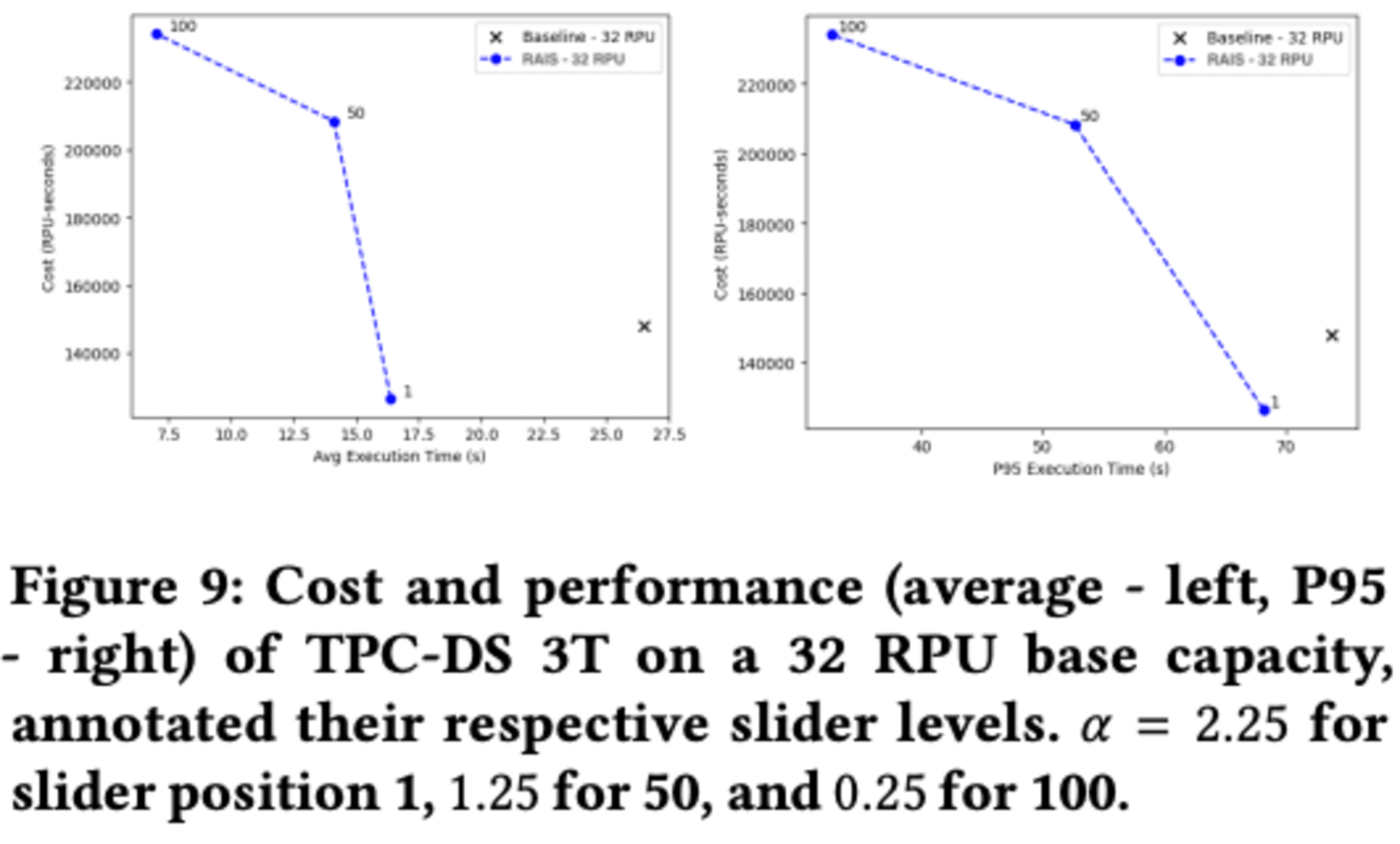
実験結果では、**RAISは現行Redshift Serverlessと比較して、コストを抑えつつ性能を向上させることができました。**特に、平均実行時間を指標とした場合、RAISはスライダーレベルに応じて1.89倍から2.4倍の価格性能比の改善を達成しました。この研究は、ユーザーが簡単に性能とコストのバランスを調整できる柔軟なデータウェアハウスシステムの可能性を示しています。
7 RELATED WORK
ワークロード管理
RAISはユーザー設定のパフォーマンス目標を最適化する研究が行われてきました。一部の研究では強化学習も活用されています。しかし、クラウド環境での実用的な課題に対応した本格的なシステムはありませんでした。既存のソリューションは単一クラスターでの動作や、既知のクエリテンプレートへの依存、正確な実行時間やリソース消費の予測を必要とするなどの制限がありました。RAISはAmazon RedshiftのAuto-WLMなど、従来のワークロード管理を基盤としていますが、CPUやメモリの割り当てを超えて、クラスター全体規模でのリソースの獲得と解放を行う点が特長です。
パラメータ最適化
RAISはデータベースシステムの自動チューニングと同様のオフラインでの手法を用いて、ベースとなるウェアハウス容量とスケーリングの積極性を調整します。ただし、実運用環境では顧客クラスターで実験を行うことができないため、制御された探索が困難です。また、ベースキャパシティの変更は顧客に影響を与える可能性があるため容易ではありません。そのため、RAISはこれらの設定を選択する際にシミュレーションに頼らざるを得ません。
8 CONCLUSION
RAISは動的な垂直スケーリングと自動ベースコンピューティングサイズ変更を提供する Amazon Redshift Serverless の機能である Redshift の AI 駆動型スケーリングと最適化 (RAIS) の背後にある技術について説明しました。RAIS は、さまざまな種類のワークロード変動にインテリジェントに適応し、最新のクラウド データ ウェアハウスの機能を拡張します。既存のベースラインと比較して、RAIS は手動による介入やワークロードの分割を必要とせずに、価格やパフォーマンスを大幅に向上できることを示しました。
最後に
re:Invent2023のキーノートで発表され、SIGMOD/PODS 2024の中で一番紹介したかった論文、Intelligent Scaling in Amazon Redshift です。
「パフォーマンス」と言っても期待しているのがレスポンスなのか、スループットなのか、オーバープロビジョニングによるコスト増を許容できるかなど、ユースケースや予算によって様々です。その様々な要望に応えるのが、Redshift Serverless の新機能(プレビュー)である RAIS(Resource Allocation and Index Selection) です。
RAISは機械学習を活用して、クエリの複雑さやデータ量などのワークロードパターンを学習し、リソースを継続的に調整します。また、自動マテリアライズドビューやソート順の最適化など、既存のAmazon Redshiftの自己チューニング機能を拡張しています。
この新機能により、Amazon Redshift Serverlessは、データ量の変化、同時実行ユーザー数、クエリの複雑さなどのワークロード変動に自動的に対応し、設定された料金パフォーマンスの目標を達成・維持することが可能になります。
利用者が設定したスライダーの位置に応じて、最適なパラメータを選択して実行を制御します。このアプローチにより、RAISは顧客の要求に合わせてデータウェアハウスのリソース配分とインデックス選択を最適化することができます。ご興味がある方は、現在、パブリックプレビューでお試しいただくことが可能です。
合わせて読みたい










